
What is analytics engineering ?

Transition into the modern data stack
Before 2012, what I call the “classic” data stack was widely used with Oracle databases typically. At that time, the first hire in a data team was most probably a data engineer who was responsible to extract the data from various sources into a specific data processing tool as Business Object Data Services (BODS). Finally, the transformed data was loaded into the data warehouse in the Oracle database. Pre 2012, the ETL (Extract, Transform and Load) paradigm constituted the basics in data warehousing.
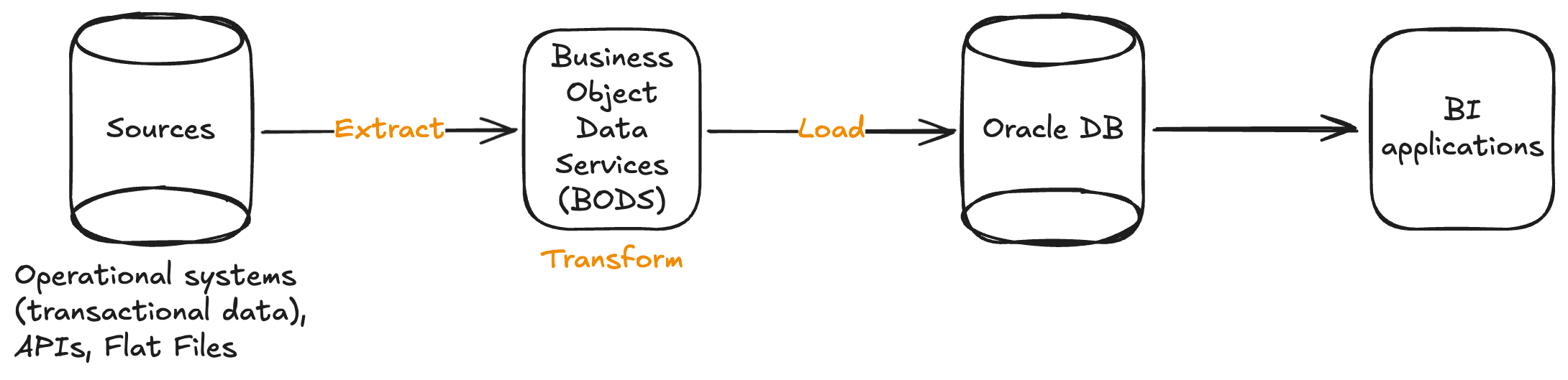
The launch of Amazon Redshift in 2012 marked a pivotal shift in data warehousing as it was one the first cloud-native data warehouses offering a scalable alternative to on-premise systems like Oracle. This introduces the shift from ETL to ELT (Extract, Load and Transform) where raw data was extracted from various sources into a Cloud environment (AWS, GCP or Azure). Once the data was ingested, it was transformed straight in the Cloud, without the need to take it out into a separate data processing tool. This new data architecture is known as the modern data stack (MDS):
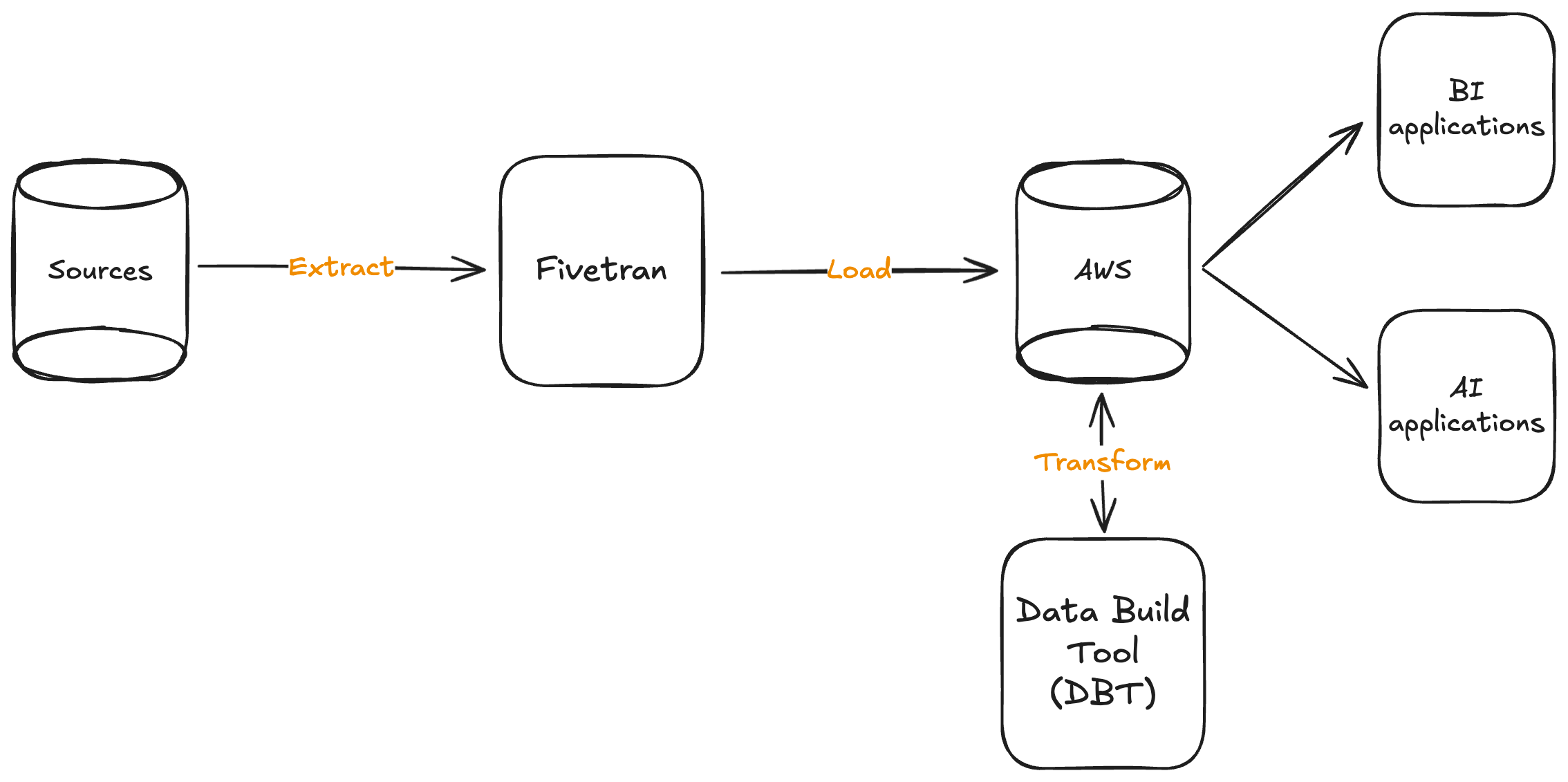
As shown in the schema above, the MDS is constituted of three main tools:
Data integration tool: Fivetran, Airbyte, Stitch are different companies which allow to extract data from various sources into a cloud environment as AWS, GCP or Azure.
Cloud data warehouse: The key component of the MDS: a cloud data warehouse as Amazon Redshift, Google BigQuery or Snowflake which store the data for BI (dashboards with Power BI, Looker, Tableau or else) or AI applications (Machine Learning, Computer Vision, …).
Data transformation: Data Build Tool (DBT) is the leader in this market. It allows to transform and process data straight in the cloud.
The arise of analytics engineers through the modern data stack
As stated above, the data architecture paradigm changed after 2012 (ETL → ELT) which induced the introduction of a whole set of new tools. Consequently, it lead to the arise of new data jobs. As stated above, it introduces the need to transform the data right in the cloud: dbt labs came in as the leader in that area.
dbt labs introduces a new job role in 2018: analytics engineer ! An analytics engineer stands at the middle of a data engineer and a data analyst. In this modern data team, the data engineer is responsible of extracting and loading the data, the data analyst or scientist is responsible of activating the data through analytics and AI applications, respectively. The analytics engineer is responsible delivering well-defined, transformed, tested, documented and code-reviewed data sets ( the “T” in “ELT”):
As shown in the schema above, the arise of analytics engineers reshaped other data roles notably the data analyst role. In some companies, even nowadays, data analysts are kinda full-stack meaning they process the data, analyse it and visualise it on a dashboard. In the modern data team, data analyst sees their perimeter shrunken as they are “only” responsible of analysing data to find business insights. Regarding the data visualisation, it is owned by BI engineers and the data modelling by analytics engineers.
Deep dive into the role of analytics engineers
As stated above, analytics engineers have an intermediate position between data engineers and data analysts. As a rule of thumb, analytics engineers spent 50% of their time working with software engineering concepts (Git, CI/CD, code version control, orchestrators as Airflow) and 50% of their time working on business oriented topics.
Analytics engineers care about problems like :
Is it possible to build a single table that allows us to answer this entire set of business questions?
What is clearest possible naming convention for tables in our warehouse?
What if I could be notified of a problem in the data before a business user finds a broken chart in Looker?
What do analysts or other business users need to understand about this table to be able to quickly use it?
How can I improve the quality of my data as its produced, rather than cleaning it downstream?
To work as an analytics engineer, here are the skills you should have (or acquire):
Core Technical: SQL, Python, dbt, Git, cloud data warehouses (e.g., Snowflake, BigQuery).
Data Modeling: Kimball dimensional modeling, star/snowflake schemas, Inmon approach, One Big Tables, ELT/ETL design.
BI & Visualisation: Understanding best practises with data visualisation tools (Looker, Tableau, Power BI) to allow the building of low latency dashboards
Collaboration: Communication with stakeholders, translating business needs to technical solutions.
Business Acumen: Understanding KPIs, domain knowledge, aligning work with organisational goals.
Stay tuned, more is coming !
Sources:
https://www.getdbt.com/analytics-engineering
https://www.getdbt.com/analytics-engineering/start-here
https://www.getdbt.com/what-is-analytics-engineering