
The Power of Modularity in dbt: Why It Matters for Analytics Engineers

Today, I’m going to talk about modularity which is the core concept of dbt.
The purpose of this article is to make you understand modularity to build strong basis in analytics engineering.
Unfortunately, many analytics engineers (AE) keep building too complicated data pipelines because they forget about the key concept dbt introduced back in 2018.
If you keep this concept in mind on your everyday work, you’ll build more robust and easier to maintain data pipelines. By doing so, you’ll differentiate yourself from your colleagues to become a top-notch AE.
Let’s dive in.
Traditional and monolithic data pipelines
Before dbt was released, monolithic data pipelines were used in the industry meaning very long SQL scripts (10 000+ lines) were used to build table, data marts, datasets.
If someone else in the organisation was looking to model similar tables, they were starting over. Indeed, modifying long SQL scripts was more difficult than starting over from source data.
This is problematic as several levels: money-wise as it costs more money to reuse source data over and over, data quality wise as a single KPI won’t be calculated the same way by two developers leading to data discrepancies and lack of confidence from business stakeholder, a high complexity when production breaks, …
Modularity: the core concept of dbt to improve the robustness of data pipelines
The best way to explain modularity is to do it through its use in the car industry.
A car is not built all at the same place, at the same time. It is separated into different parts (chassis, engine, suspension, electronic systems, …) which are designed and built as independent modules. These modules can then be assembled together to form the final car.
The core concept of dbt is apply modularity to data pipelines ! How ? By designing data pipelines as independent modules which are assembled at the final stage to form the final data mart.

This induces lots of benefits:
Reusability: No need to start over from the source everytime. Every data producer from the same company can reuse SQL code, macros and dbt models developed by other colleagues
→ Reduces duplication of code
→ Makes pipelines easier to manageCollaboration and Team Efficiency: Enable teams to work on different parts of the pipeline simultaneously
→ Saves time and money as data pipelines can be built quicker
→ Forces to use version control to keep track of modificationsEasier debugging and maintenance: Simpler to understand and fix issues in data pipelines
→ Saves time and money to focus on more valuable tasks
Using dbt doesn’t guarantee you’ll build modular data models
Back to the beginning of this article, I said that lots of AE keep building too complex data pipelines even if they’re using dbt! Why so ? Because, they forgot about the key concept upon which dbt was built: modularity.
Don’t forget that the tool shouldn’t define you but you should define the tool by properly using it. The tool is a mean to get to where you want. When building data pipelines for your data analysts, BI engineers or data scientists, you have to keep this concept in mind to make the most modular data pipeline you can. This will enhance a lot more your final data project (e.g Tableau dashboard) and the maintenance of it will be much easier for you !
You make the tool, not the opposite !
How modularity translates in dbt
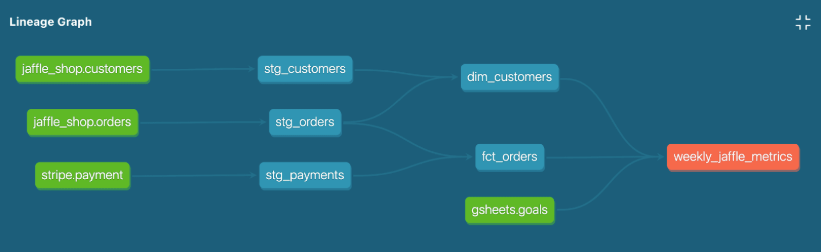
Staging, intermediate and mart models are the consequence of modularity in dbt ! When you’re initialise a dbt project, by default, you’ll have the staging, intermediate and mart folders as shown below:

Staging models
Staging models have to be the first models right after the source data. In staging models, only light transformations should be applied (choosing a subset of columns, CAST, WHERE, …). As a best practise, you should use the prefix stg_ for your staging models. Important to keep in mind that you have to have a 1-to-1 relationship between staging models and source data:

Intermediate models
Intermediate models are optional. You should use them if you have too many transformations from your staging zone to your final (mart) zone. If you need to use intermediate models, you have to put more advanced changes at that stage (JOINS, CASE WHEN, window functions). As a best practise, you should use the prefix int_ for your intermediate models.
Mart models
This is your final layer, the tables which will constitute the data mart of your team and most probably the source for your activation layer which will be the direct backend of your dashboards (I’ll get into that in another newsletter).
Best practises:
For staging models, use the prefix stg_
For intermediate models, use the prefix int_
Materialise staging and intermediate models as ephemeral models.
It will avoid building unnecessary tables or views which will save money.
Whenever you have a bug in production, you’ll be able to materialise these models into tables to fix your issue.
For mart models, use the prefix dim_ for dimensions, fact_ for fact tables and obt_ for One Big Tables
Key takeaways
Modularity is the powerful concept which made dbt so strong on the market
Modularity consists into building a final product using independent modules
Modularity translates into dbt through the use of staging, intermediate and mart models
That's all for today.
See you next Tuesday.